Random Research Ideas
1) In the Beginning of Infinity, physicist and quantum computing researcher David Deutsch proposes the following experiment: find some robot that is already used in the real world and happens to be able to walk. Replace the robot’s existing code with completely random code (“random numbers”, in his words) and implement a system that allows small bits of the code to randomly “mutate”, similar to genetic mutation. The idea behind using random numbers is to totally preclude the possibility that human knowledge is somehow being transfered to the robot. Given enough mutations and time, will the robot ever learn to walk? Has anybody every simulated this experiment?
2) How can we assess a language model’s performance at tasks in which scoring is arguably subjective, e.g. summarization? For example, if I ask an LLM to summarize a piece of text, how do you determine whether the summary is good or bad? How do you quantify this sort of question? One suggestion I’ve heard is to try breaking down the task into something more achievable. One resource I was looking at suggests drawing an analogy to flashcards - suppose that the summary of the text consists of a bunch of “flashcards” and evaluate every flash card individually. Go through every flash card and ask questions like, are the dates right? Does it mention the relevant key words? Are there any key words in this flash card which shouldn’t be there? (source: “How to Build Terrible AI Systems”)
3) Is it possible to generate a constructed language using AI? If the language was more “concise” than English (e.g. it takes 150 characters to express a thought that would take 200 characters in English), would there be any practical value to it over English? (Douglas Hofstader alludes to this idea in Godel, Escher, Bach when he talks about translation between languages by means of an intermediate langauge as opposed to dictionary lookup.)
4) Will it ever be possible to extend large language model context windows to infinite length? Some solutions to this problem that I’ve researched are MemGPT (which uses a memory hierarchy similar to how OSes work) and Grouped Attention.
5) How can we get language models to achieve “superhuman” performance on tasks that that even humans can’t do? For example, given a grammar for an arbitrary language, can we get models to output grammatical sentences in that language? More generally, if I give an LLM a detailed specification of some system (be it a language, a writing system like VJScript, or something else altogether) which has dozens, hundreds, or even thousands of rules, how can I get a language model to produce outputs which adhere to all these rules without giving it a lot of examples?
6) Given a silent MRI video of somebody talking, is it possible to train an ML model to detect what language they are speaking?
7) Suppose there exist two languages, language X and language Y. X and Y are sufficiently different from each other to be considered separate languages, but they still have a lot of shared vocabulary (e.g. English/French, Spanish/Italian). What is the most efficient way to generate sentences in language X that have high mutual intelligiblity for speakers of language Y?
For example, the French sentence below is mostly intelligible to a speaker of English:
“Le président Emmanuel Macron assure le peuple canadien que le gouvernement français va continuer à défendre le Canada contre la menace américain.”
Even if you didn’t catch any word, you can get the gist of it – the French president Emmanuel Macron is assuring the “peuple canadien” (Canadian people) about something involving the “gouvernment français” (French government). Imagine reading thousands of sentences like this – it would be a great way to “backdoor” into a new language using cognates you already know. Solving this problem will probably involve NLP, statistics, and some kind of cognate detection tool. I’ve made a simple demo of this concept here.
8) Is it possible to design a writing system that combines English consonant letters with Abugida-style vowel diacritics? For example, the letter “B” would be written “B” and the letter “BA” would be written “Bा. “BI”, “BO”, and “BU” would be “िB” “Bो”, and “Bु” respectively. Here’s an example:
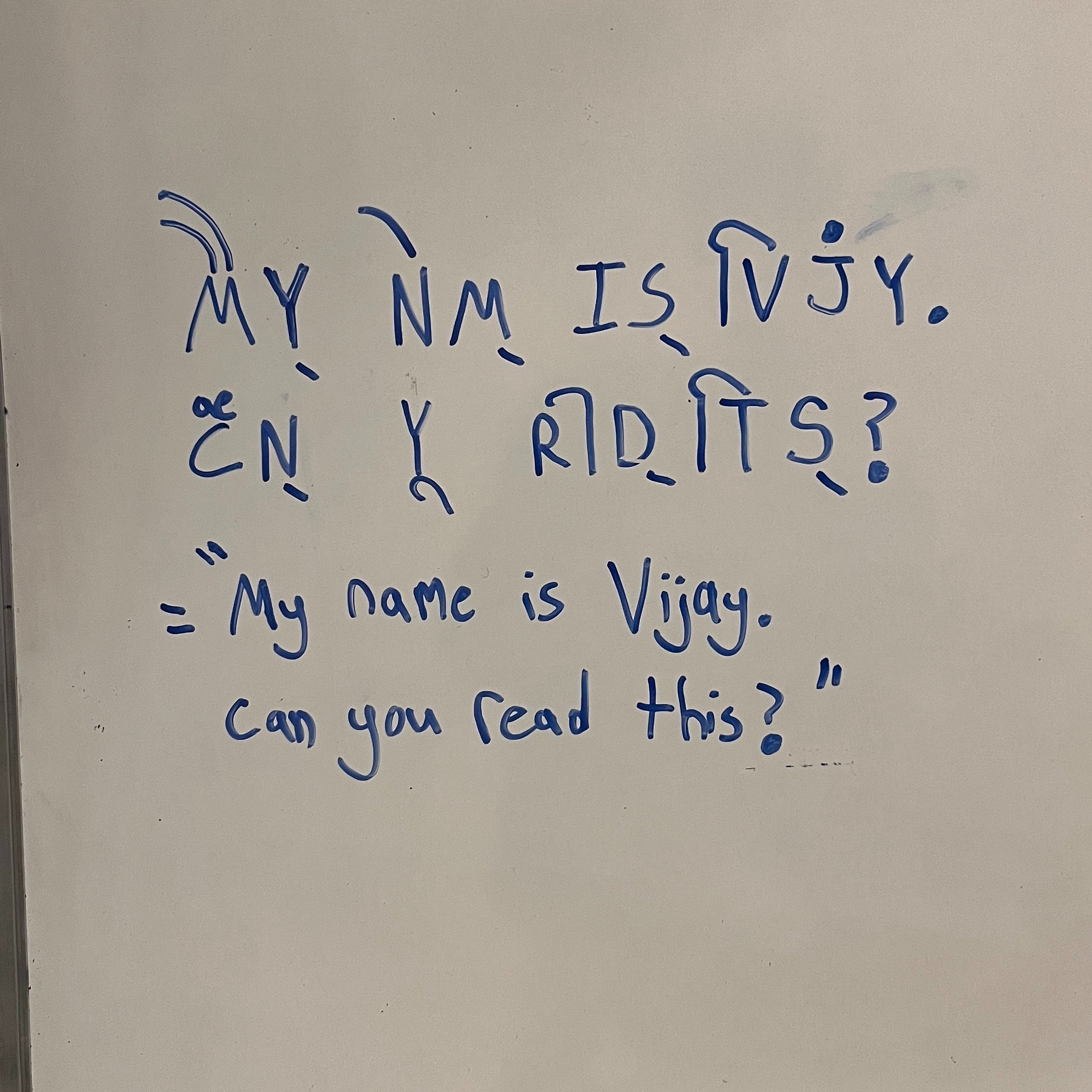
Here’s another example, with diacritics exclusively on top of the words:
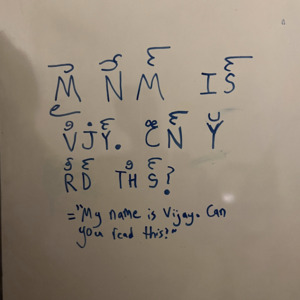
Update: I ended up writing a blog post about this, see my “writings” tab for more info.